What is computer vision? We just don't know...*
Actually, we do know. Computer vision is having computers look at/interpret/understand images of the real world. While it's still sort of fresh in my mind, I'm going to list some of the interesting papers I saw at CVPR (Computer Vision and Pattern Recognition) 2013 that will hopefully give a sense of what people study and publish on in computer vision.
*allusion to the Water episode of Look Around You because I can't help but make semi-obscure jokes in my blog posts...



Anyway, that's just a small sampling of what was going on at CVPR this year!
Actually, we do know. Computer vision is having computers look at/interpret/understand images of the real world. While it's still sort of fresh in my mind, I'm going to list some of the interesting papers I saw at CVPR (Computer Vision and Pattern Recognition) 2013 that will hopefully give a sense of what people study and publish on in computer vision.
*allusion to the Water episode of Look Around You because I can't help but make semi-obscure jokes in my blog posts...
Papers papers papers!
-
Fine-Grained Crowdsourcing for Fine-Grained Recognition
- Jia Deng, Jonathan Krause, Li Fei-Fei
- http://vision.stanford.edu/documents/DengKrauseFei-Fei_CVPR2013.pdf
- This is the paper I mentioned before with the Bubbles game! Basically, a game that teaches the computer why an image should be classified as one thing and not another

- Dense Variational Reconstruction of Non-Rigid Surfaces from Monocular Video
- Ravi Garg, Anastasios Roussos, Lourdes Agapito
- http://www.eecs.qmul.ac.uk/~rgarg/Variational_NRSfM/
- I didn't know this was possible, making a 3D shape from a video of a face, especially with no face template (not even knowing it's a face)! The main trick is that the guy moves his head around a little bit from side to side, and by some magic, that is enough to provide 3D information.

-
Supervised Descent Method and its Applications to Face Alignment
- Xuehan Xiong, Fernando DelaTorre
- http://www.ri.cmu.edu/pub_files/2013/5/main.pdf
- http://www.humansensing.cs.cmu.edu/intraface/
- I had mentioned this face tracker before, too. In the live demo, it was super slick! I had a hard time fooling it, even covering my face with hair and opening my mouth really wide.

- Lost! Leveraging the Crowd for Probabilistic Visual Self-Localization
- Marcus Brubaker (TTI Chicago), Andreas Geiger (KIT & MPI Tubingen), Raquel Urtasun (TTI Chicago)
- http://www.cs.toronto.edu/~mbrubake/projects/map/
- The idea of this paper was that given an map, and driving a car around some roads represented by that map, you could figure out where you were by looking at odometry and how the car was turning. Basically, by capturing turns and how far you'd driven between turns, you could see where that would fit on a map and make a good guess as to where you were.
- The awkward things about this paper, especially as I actually read it now, is that:
- It's not using any visual clues about where the car is... so I don't know where the vision is
- I don't believe that using OpenStreetMap data counts as "leveraging the crowd". It's just using map data that happened to be put together by "the crowd"/not a mapping company. It's even less crowdsourcey than mining photos from Flickr, where at least you're tapping into this weird human-nature-what-do-people-take-photos-of thing. What do humans map using OSM? People interested in mapping map things that need to be mapped.
- Their approach DOES, however, feel very much like what I would do as a human if I were lost. I'd walk and look at the shape of the road/terrain for clues and then I'd walk more to confirm my hypothesis.


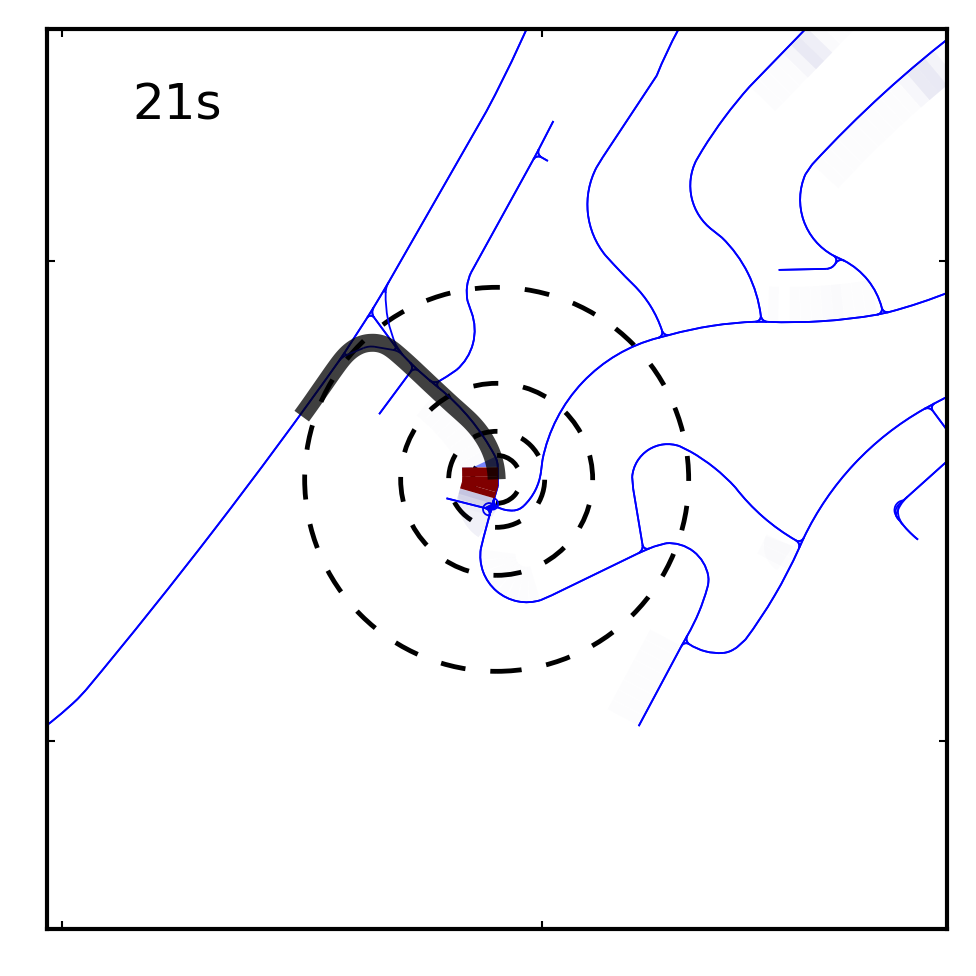 |
| A car driving and hypothesizing about its location on a map |
- Fast, Accurate Detection of 100,000 Object Classes on a Single Machine
- Thomas Dean, Jay Yagnik, Mark Ruzon, Mark Segal, Jonathon` Shlens, Sudheendra Vijayanarasimhan
- The answer is... use a hash table! That's the answer to pretty much every Google interview question, and it should not be surprising that this paper is from Google Research. But seriously, this does seem like a nice, clever, scalable way to do things.
- Bringing Semantics Into Focus Using Visual Abstraction
- Larry Zitnick, Devi Parikh
- http://research.microsoft.com/en-us/um/people/larryz/clipart/abstract_scenes.html
- Larry is at MSR and has ties to UW, so I actually saw a sneak peek of this at the GRAIL retreat last fall. He also has a neat and unrelated paper on Handwriting Beautification appearing at Siggraph this summer.
- The point of this paper is that we can start doing scene understanding before all the hard parts like object recognition are completely figured out. Just use objects that you already know about (these cute clipart things) and have people on the internet make a variety of scenes.
- They had people make random scenes, then make sentences from those scenes, and then from 1000 sentences, make 10 more scenes for each sentence. Then they studied which visual features were meaningful and which words were meaningful, and were able to automatically learn some pretty common sense knowledge.
- The end message was that even though the system appeared to learn "obvious" things (for humans, anyway) these things were not necessarily obvious to computers, but this approach of having people create clipart scenes was an automated way of learning common sense knowledge.
- Also, people on Mturk thought it was super fun because they got to be creative!

- Higher is Better: High-dimensional Feature and Its Efficient Compression for Face Verification
- Dong Chen, Xudong Cao, Fang Wen, Jian Sun
- http://research.microsoft.com/apps/pubs/?id=192106
- The two main points of this paper were:
- You're not using enough features to do face recognition! You could use way more and be way better at it! How about multi-scale descriptors at dense landmarks?
- We suggested you use a lot of features and that's kind of scary, hard, and computationally expensive, so here's a trick for using a sparse representation for these large features that makes things work out okay in the end.
- Exemplar-Based Face Parsing
- Brandon Smith, Li Zhang, Jonathan Brandt, Zhe Lin, Jianchao Yang
- http://pages.cs.wisc.edu/~lizhang/projects/face-parsing/
- One of the reasons this was cool is that other face landmark techniques just find points, like the corners of the eyes/mouth/nose. This technique would find whole patches and even represent ambiguity like the region between the nose and the cheek being a mixture between those two regions.

Anyway, that's just a small sampling of what was going on at CVPR this year!
Hi Nice blog. checkout Greeleydental.com
ReplyDeleteYou are awesome. Need a Dentist?
ReplyDelete